assignment 4 big data (prediksi elektabilitas caleg) solved using rapidminer
Rapid Miner is a data science software platform developed by the company of the same name that provides an integrated environment for data preparation, machine learning, deep learning, text mining, and predictive analytics. It is used for business and commercial applications as well as for research, education, training, rapid prototyping, and application development and supports all steps of the machine learning process including data preparation, results visualization, model validation and optimization
the reason why i choose rapidminer is because it is easy to use and it responded rapidly based on the instruction that is given, i will do the prediction by using three different models. those models are; decision tree, naive bayes & k-nearest neighbor.
prediction using decision tree.
This Operator can process ExampleSets containing both nominal and numerical Attributes. The label Attribute must be nominal.
After generation, the decision tree model can be applied to new Examples using the Apply Model Operator. Each Example follows the branches of the tree in accordance to the splitting rule until a leaf is reached.

result:
 the decision tree diagram
the decision tree diagram
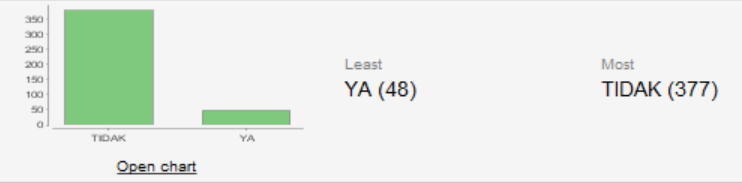
 the result of the prediction conclude that 48 says YA and 377 says TIDAK
the result of the prediction conclude that 48 says YA and 377 says TIDAK
this model accuracy is 96.38%
prediction using naive bayes.
The advantage of the Naive Bayes classifier is that it only requires a small amount of training data to estimate the means and variances of the variables necessary for classification. Because independent variables are assumed, only the variances of the variables for each label need to be determined and not the entire co-variance matrix.


 result based on "NAMA CALON LEGISLATIF"
result based on "NAMA CALON LEGISLATIF"

result based on "JENIS KELAMIN"

result based on"KECAMATAN"
result based on "NO. URUT PARPOL"

result based on "SUARA SAH PARTAI"

result based on "JML.PEROLEHAN KURSI"

result based on " DAERAH PEMILIHAN"

result based on"NO.URUT CALEG"

result based on"SUARA SAH CALEG"

end result TERPILIH ATAU TIDAK TERPILIH the majority says TIDAK.

the result of the prediction conclude that 48 says YA and 377 says TIDAK
this prediction model accuracy is 97.12%
prediction using K-NN
The k-nearest neighbor algorithm is amongst the simplest of all machine learning algorithms: an example is classified by a majority vote of its neighbors, with the example being assigned to the class most common amongst its k nearest neighbors (k is a positive integer, typically small). If k = 1, then the example is simply assigned to the class of its nearest neighbor.The same method can be used for regression, by simply assigning the label value for the example to be the average of the values of its k nearest neighbors. It can be useful to weight the contributions of the neighbors, so that the nearer neighbors contribute more to the average than the more distant ones.
The neighbors are taken from a set of examples for which the correct classification (or, in the case of regression, the value of the label) is known. This can be thought of as the training set for the algorithm, though no explicit training step is required.
The basic k-Nearest Neighbor algorithm is composed of two steps: Find the k training examples that are closest to the unseen example. Take the most commonly occurring classification for these k examples (or, in the case of regression, take the average of these k label values).

result:
 the result of the prediction conclude that 48 says YA and 377 says TIDAK.
the result of the prediction conclude that 48 says YA and 377 says TIDAK.
this prediction model accuracy is 96.02%
the reason why i choose rapidminer is because it is easy to use and it responded rapidly based on the instruction that is given, i will do the prediction by using three different models. those models are; decision tree, naive bayes & k-nearest neighbor.
prediction using decision tree.
Description
A decision tree is a tree like collection of nodes intended to create a decision on values affiliation to a class. Each node represents a splitting rule for one specific Attribute. This rule separates values belonging to different classes in an optimal way for the selected parameter criterion. The building of new nodes is repeated until the stopping criteria are met. A prediction for the class label Attribute is determined depending on the majority of Examples which reached this leaf during generation.This Operator can process ExampleSets containing both nominal and numerical Attributes. The label Attribute must be nominal.
After generation, the decision tree model can be applied to new Examples using the Apply Model Operator. Each Example follows the branches of the tree in accordance to the splitting rule until a leaf is reached.
- open rapidminer the choose new process.
- determine the validation rules.
- do the validation start by training and then choose decision tree.
- create the model
- run the model.


prediction using naive bayes.
Description
A Naive Bayes classifier is a simple probabilistic classifier based on applying Bayes' theorem (from Bayesian statistics) with strong (naive) independence assumptions. A more descriptive term for the underlying probability model would be 'independent feature model'. In simple terms, a Naive Bayes classifier assumes that the presence (or absence) of a particular feature of a class (i.e. attribute) is unrelated to the presence (or absence) of any other feature. For example, a fruit may be considered to be an apple if it is red, round, and about 4 inches in diameter. Even if these features depend on each other or upon the existence of the other features, a Naive Bayes classifier considers all of these properties to independently contribute to the probability that this fruit is an apple.The advantage of the Naive Bayes classifier is that it only requires a small amount of training data to estimate the means and variances of the variables necessary for classification. Because independent variables are assumed, only the variances of the variables for each label need to be determined and not the entire co-variance matrix.
- open rapidminer the choose new process.
- determine the validation rules.
- do the validation start by training and then choose naive bayes.
- create the model
- run the model.

results :
SimpleDistribution

 result based on "NAMA CALON LEGISLATIF"
result based on "NAMA CALON LEGISLATIF" 
result based on "JENIS KELAMIN"

result based on"KECAMATAN"
result based on "NO. URUT PARPOL"

result based on "SUARA SAH PARTAI"

result based on "JML.PEROLEHAN KURSI"

result based on " DAERAH PEMILIHAN"

result based on"NO.URUT CALEG"

result based on"SUARA SAH CALEG"

end result TERPILIH ATAU TIDAK TERPILIH the majority says TIDAK.

the result of the prediction conclude that 48 says YA and 377 says TIDAK
prediction using K-NN
Description
The k-Nearest Neighbor algorithm is based on learning by analogy, that is, by comparing a given test example with training examples that are similar to it. The training examples are described by n attributes. Each example represents a point in an n-dimensional space. In this way, all of the training examples are stored in an n-dimensional pattern space. When given an unknown example, a k-nearest neighbor algorithm searches the pattern space for the k training examples that are closest to the unknown example. These k training examples are the k "nearest neighbors" of the unknown example. "Closeness" is defined in terms of a distance metric, such as the Euclidean distance.The k-nearest neighbor algorithm is amongst the simplest of all machine learning algorithms: an example is classified by a majority vote of its neighbors, with the example being assigned to the class most common amongst its k nearest neighbors (k is a positive integer, typically small). If k = 1, then the example is simply assigned to the class of its nearest neighbor.The same method can be used for regression, by simply assigning the label value for the example to be the average of the values of its k nearest neighbors. It can be useful to weight the contributions of the neighbors, so that the nearer neighbors contribute more to the average than the more distant ones.
The neighbors are taken from a set of examples for which the correct classification (or, in the case of regression, the value of the label) is known. This can be thought of as the training set for the algorithm, though no explicit training step is required.
The basic k-Nearest Neighbor algorithm is composed of two steps: Find the k training examples that are closest to the unseen example. Take the most commonly occurring classification for these k examples (or, in the case of regression, take the average of these k label values).
- open rapidminer the choose new process.
- determine the validation rules.
- do the validation start by training and then choose knn.
- create the model
- run the model.

result:
KNNClassification
1-Nearest Neighbour model for classification. The model contains 425 examples with 10 dimensions of the following classes: HATI NURANI RAKYAT PARTAI KARYA PEDULI BANGSA PARTAI PENGUSAHA DAN pekerja indonesia PARTAI PEDULI RAKYAT PARTAI GERINDRA PARTAI BARISAN NASIONAL PARTAI KEADILAN PERSATUAN INDONESIA PARTAI KEADILAN SEJAHTERA PARTAI AMANAT NASIONAL PARTAI KEDAULATAN PARTAI PERSATUAN DAERAH PARTAI KEBANGKITAN BANGSA PARTAI NASIONAL INDONESIA MARHAENISME PARTAI DEMOKRASI PEMBARUAN PARTAI MATAHARI BANGSA PARTAI PENEGAK DEMOKRASI INDONESIA PARTAI DEMOKRASI KEBANGSAAN PARTAI PELOPOR PARTAI GOLONGAN KARYA PARTAI PERSATUAN PEMBANGUNAN PARTAI NASIONAL BENTENG KERAKYATAN INDONESIA PARTAI BULAN BINTANG PARTAI DEMOKRASI INDONESIA PERJUANGAN PARTAI BINTANG REFORMASI PARTAI PATRIOT PARTAI DEMOKRAT PARTAI INDONESIA SEJAHTERA PARTAI KEBANGKITAN INDONESIA PARTAI PERSATUAN NAHDLATUL UMMAH INDONESIA PARTAI BURUH

this prediction model accuracy is 96.02%

Komentar
Posting Komentar